CRI-RM赋能浪潮AIStation 释放云原生AI工作负载的澎湃性能
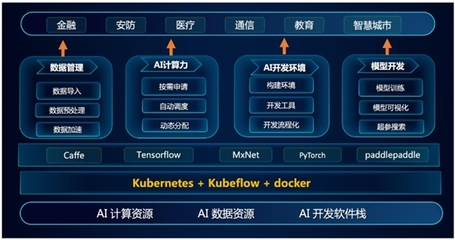
在人工智能浪潮席卷全球的当下,高效、灵活且可扩展的基础设施已成为驱动AI创新与落地的核心引擎。浪潮AIStation作为领先的企业级人工智能开发平台,正持续深化其云原生能力,以满足日益复杂的模型训练与推理需求。而在此进程中,容器运行时接口资源管理器(CRI-RM)的深度集成与应用,正成为其大幅提升云原生工作负载性能、优化资源利用率的关键技术支柱。
云原生与AI工作负载的融合挑战
传统的AI开发与部署,尤其在GPU等稀缺加速器资源的管理上,常面临资源静态分配、利用率低下、环境隔离与部署运维复杂等痛点。云原生技术以其弹性伸缩、敏捷交付和统一运维的优势,为AI应用提供了理想的运行框架。标准的Kubernetes在管理GPU、RDMA等异构硬件资源时,其默认的调度与分配机制往往不够精细,难以充分释放硬件的全部潜力,尤其是在多任务、多租户的高并发场景下,资源争抢与性能隔离问题凸显。
CRI-RM:精细化资源管理的核心利器
CRI-RM是Kubernetes生态中一个专注于容器运行时资源管理的插件。它作用于Kubelet与容器运行时(如containerd、CRI-O)之间,能够对Pod申请的资源进行更细粒度的管控和动态分配。其核心价值在于:
- 增强的资源感知与分配:能够精确识别和管理节点上的各类设备资源(如GPU卡、GPU内存、特定型号AI加速卡、高速网络设备),并支持更灵活的分配策略,如GPU时间片共享、显存隔离等。
- 提升资源利用率:通过支持资源超售、动态共享和碎片整理,CRI-RM可以让单个物理GPU同时安全地服务多个轻量级推理任务,或将零散的资源组合分配给合适的任务,从而显著提升昂贵硬件资源的整体使用效率。
- 保障性能与隔离性:它能够实施严格的资源限额与隔离策略,确保高优先级任务获得承诺的性能,避免不同工作负载间的相互干扰,这对于生产环境的稳定性和SLA保障至关重要。
浪潮AIStation的整合与实践
浪潮AIStation通过深度集成CRI-RM,构建了更加智能和高效的AI资源调度与管理层:
1. 智能化GPU资源调度:
AIStation利用CRI-RM提供的细粒度GPU信息,实现了超越“每Pod整卡分配”的灵活策略。平台可以按算力核心、显存大小或组合维度进行分割与调度,例如将一块A100 GPU同时分配给多个模型微调或在线推理服务,使资源利用率提升数倍。调度器能根据任务特性和优先级,智能选择独占或共享模式。
2. 端到端性能优化:
在训练任务中,CRI-RM协助AIStation实现GPU与高性能网络(如InfiniBand)的亲和性绑定,确保计算与通信流水线的高效重叠。在推理场景,结合CRI-RM的细粒度资源控制,AIStation可以实现推理服务的动态扩缩容和混合部署,在保证延迟的前提下,大幅提升服务密度和吞吐量。
3. 统一运维与多租户隔离:
平台通过CRI-RM强化了租户间的资源隔离与审计能力。每个AI项目或团队获得的资源视图清晰,性能表现可预测,避免了“邻居噪音”问题。运维人员可以通过AIStation的统一界面,直观监控底层资源的实际消耗与健康状态,实现从应用到基础设施的闭环管理。
4. 加速AI开发全流程:
从交互式开发、分布式训练到模型部署,CRI-RM提供的弹性资源池使得AIStation能够快速响应开发者不断变化的资源需求。开发环境可以快速拉起并精确匹配所需资源,训练任务可以动态调整资源配比以缩短迭代周期,模型服务可以根据负载自动伸缩。
构筑高性能AI基础软件新生态
CRI-RM与浪潮AIStation的深度融合,标志着AI基础软件栈在云原生方向上的成熟演进。它不仅是技术组件的简单叠加,更是对AI算力资源管理范式的一次革新。通过将底层的、精细化的资源控制能力,与上层平台级的智能调度、运维管理和用户体验相结合,浪潮AIStation成功构建了一个高性能、高利用率、高易用性的AI云原生操作系统。
随着AI模型规模持续扩大和应用场景日益复杂,对底层资源的智能化、精细化管控需求将只增不减。以CRI-RM为代表的技术将持续进化,并与AIStation等平台更紧密协作,共同构筑更加坚实、灵活和高效的AI基础设施,赋能千行百业的智能化转型,释放人工智能的无限潜能。
如若转载,请注明出处:http://www.ddfwl.com/product/13.html
更新时间:2026-06-19 21:32:30